
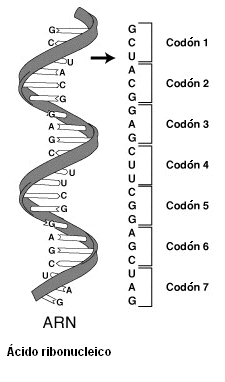
El código genético es un conjunto de normas por las que la información codificada en el material genético (secuencias de ADN o ARN) se traduce en proteínas (secuencias de aminoácidos) en las células vivas. El código define la relación entre secuencias de tres nucleótidos, llamadas codones, y aminoácidos. Un codón se corresponde con un aminoácido específico. El ARN se basa en transportar un mensaje del ADN a la molécula correspondiente
La secuencia del material genético se compone de cuatro bases nitrogenadas distintas, que tienen una función equivalente a letras en el código genético: adenina (A), timina (T), guanina (G) y citosina (C) en el ADN y adenina (A), uracilo (U), guanina (G) y citosina (C) en el ARN.
Debido a esto, el número de codones posibles es 64, de los cuales 61 codifican aminoácidos (siendo además uno de ellos el codón de inicio, AUG) y los tres restantes son sitios de parada (UAA, llamado ocre; UAG, llamado ámbar; UGA, llamado ópalo). La secuencia de codones determina la secuencia aminoacídica de una proteína en concreto, que tendrá una estructura y una función específicas.
Descubrimiento del código genético

Cuando James Watson, Francis Crick, Maurice Wilkins y Rosalind Franklin crearon el modelo de la estructura del ADN, se comenzó a estudiar en profundidad el proceso de traducción en las proteínas.
En 1955, Severo Ochoa y Marianne Grunberg-Manago aislaron la enzima polinucleótido fosforilasa, capaz de sintetizar ARNm sin necesidad de modelo a partir de cualquier tipo de nucleótidos que hubiera en el medio. Así, a partir de un medio en el cual tan sólo hubiera UDP (urdín difosfato) se sintetizaba un ARNm en el cual únicamente se repetía el ácido urídico, el denominado poli-U (....UUUUU....).
George Gamow postuló que un código de codones de tres bases debía ser el empleado por las células para codificar la secuencia aminoacídica, ya que tres es el número entero mínimo que con cuatro bases nitrogenadas distintas permiten más de 20 combinaciones (64 para ser exactos).
Los codones constan de tres nucleótidos fue demostrado por primera vez en el experimento de Crick, Brenner y colaboradores. Marshall Nirenberg y Heinrich J. Matthaei en 1961 en los Institutos Nacionales de Salud descubrieron la primera correspondencia codón-aminoácido. Empleando un sistema libre de células, tradujeron una secuencia ARN de poli-uracilo (UUU...) y descubrieron que el polipéptido que habían sintetizado sólo contenía fenilalanina. De esto se deduce que el codón UUU específica el aminoácido fenilalanina. Continuando con el trabajo anterior, Nirenberg y Philip Leder fueron capaces de determinar la traducción de 54 codones, utilizando diversas combinaciones de ARNm, pasadas a través de un filtro que contiene ribosomas. Los ARNt se unían a tripletes específicos.
Posteriormente, Har Gobind Khorana completó el código, y poco después, Robert W. Holley determinó la estructura del ARN de transferencia, la molécula adaptadora que facilita la traducción. Este trabajo se basó en estudios anteriores de Severo Ochoa, quien recibió el premio Nobel en 1959 por su trabajo en la enzimología de la síntesis de ARN. En 1968, Khorana, Holley y Nirenberg recibieron el Premio Nobel en Fisiología o Medicina por su trabajo.
El código genético es compartido por todos los organismos conocidos, incluyendo virus y organelos, aunque pueden aparecer pequeñas diferencias. Así, por ejemplo, el codón UUU codifica el aminoácido fenilalanina tanto en bacterias, como en arqueas y en eucariontes. Este hecho indica que el código genético ha tenido un origen único en todos los seres vivos conocidos.
Gracias a la genética molecular, se han distinguido 22 códigos genéticos, que se diferencian del llamado código genético estándar por el significado de uno o más codones. La mayor diversidad se presenta en las mitocondrias, orgánulos de las células eucariotas que se originaron evolutivamente a partir de miembros del dominio Bacteria a través de un proceso de endosimbiosis. El genoma nuclear de los eucariotas sólo suele diferenciarse del código estándar en los codones de iniciación y terminación.
- Yang et al. 1990. In Reaction Centers of Photosynthetic Bacteria. M.-E. Michel-Beyerle. (Ed.) (Springer-Verlag, Germany) 209-218.
- Genetic Algorithms and Recursive Ensemble Mutagenesis in Protein Engineering http://www.complexity.org.au/ci/vol01/fullen01/html/
No hay comentarios:
Publicar un comentario